Autoscaling is one of the most celebrated features in Kubernetes.
Traffic increases?
Add more pods.
CPU spikes?
Scale horizontally.
Everything appears automated and resilient.
But in many production environments, autoscaling does not actually solve the underlying problem.
It often hides it.
And sometimes, it amplifies it.
The Common Assumption About Autoscaling
Most teams assume:
“If the application is under load, scaling more replicas will fix it.”
This assumption works only when the bottleneck is truly compute capacity.
But distributed systems rarely fail because of CPU alone.
Real production bottlenecks are usually:
• dependency saturation
• database connection exhaustion
• retry storms
• lock contention
• network latency
• DNS delays
• resource throttling
• queue congestion
Adding more replicas does not solve these issues.
It increases pressure on them.
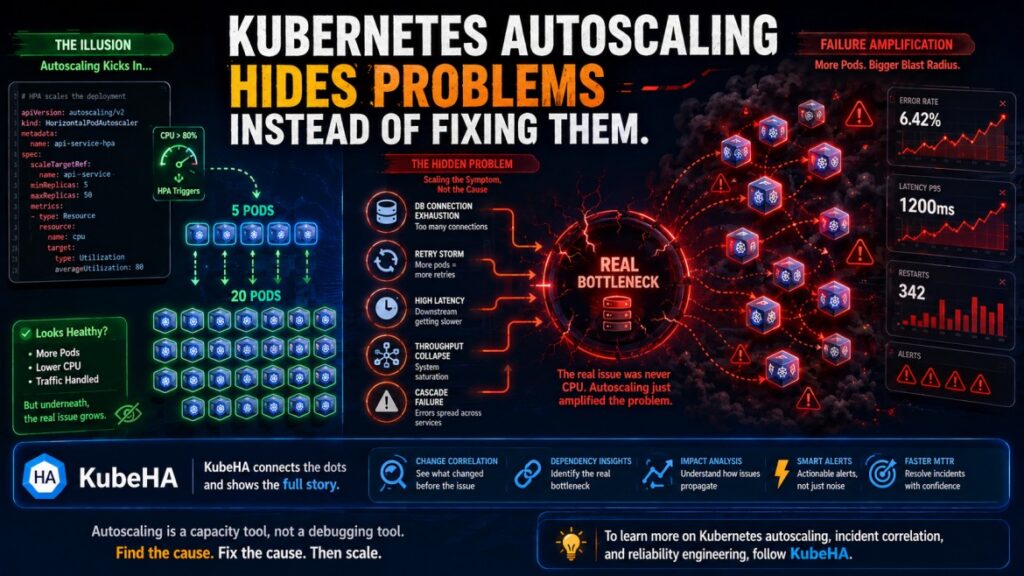
Real Production Scenario
Consider this pattern:
Initial Event
Traffic spike occurs.
Kubernetes Reaction
HPA detects:
CPU > 80%
Pods scale from:
5 → 20 replicas
What Actually Happens
Each new pod:
• opens DB connections
• increases cache requests
• increases network calls
• generates more retries
The real bottleneck – the database – becomes overloaded.
Latency increases further.
Retries amplify traffic.
Now the system experiences:
• cascading failures
• connection exhaustion
• timeout storms
Autoscaling technically “worked.”
But reliability became worse.
Why Autoscaling Creates False Confidence
Autoscaling often masks symptoms temporarily.
You see:
✅ more replicas
✅ CPU drops briefly
✅ cluster appears responsive
But underneath:
• dependency latency increases
• retry traffic grows
• resource pressure spreads
• instability propagates across services
This delays identification of the actual root cause.
The Hidden Problem: Scaling Symptoms Instead of Causes
HPA reacts to metrics like:
• CPU usage
• memory usage
• custom metrics
But these metrics measure effects, not causes.
Example:
High CPU → symptom
Root cause might be:
• slow dependency
• lock contention
• inefficient retry logic
• bad deployment
• config regression
Scaling pods only increases the scale of the symptom.
Autoscaling Can Amplify Failures
This is one of the most misunderstood behaviors in Kubernetes.
Autoscaling may increase:
🔥 Retry Amplification
More pods → more retries → more downstream load
🔥 Database Saturation
More replicas → more DB connections
🔥 Cache Contention
More replicas → more cache misses and invalidations
🔥 Network Congestion
More service-to-service traffic
🔥 Node Pressure
Rapid scaling may create:
• scheduling delays
• image pull storms
• memory fragmentation
Why Traditional Monitoring Misses This
Most dashboards show:
• HPA events
• pod count
• CPU metrics
But they rarely correlate:
• deployment changes
• dependency latency
• retries
• pod restart behavior
• downstream saturation
This creates the illusion that autoscaling solved the issue.
In reality, the underlying instability still exists.
What Mature SRE Teams Actually Focus On
Experienced SRE teams do not treat autoscaling as a reliability feature.
They treat it as a capacity management tool.
True resilience requires:
🔗 Dependency Awareness
Understanding downstream bottlenecks
⚡ Backpressure Handling
Preventing overload propagation
🧠 Retry Control
Avoiding retry storms
🔍 Root Cause Visibility
Identifying why scaling occurred
⏱️ Change Correlation
Understanding what changed before scaling started
How KubeHA Helps
KubeHA helps teams move beyond reactive autoscaling analysis.
Instead of only showing:
Pods scaled from 5 → 20
KubeHA correlates:
• HPA events
• deployment changes
• dependency latency
• pod restarts
• retry spikes
• Kubernetes events
• metrics anomalies
into a unified operational context.
Example Insight From KubeHA
Instead of guessing, teams can see:
“HPA triggered after latency spike caused by payment-service slowdown following deployment v3.2. Retry traffic increased 4x, leading to DB saturation.”
This changes incident response completely.
Engineers stop treating autoscaling as the issue and start identifying:
✅ why scaling occurred
✅ which dependency degraded first
✅ how the failure propagated
Operational Benefits
Teams using correlation-driven analysis achieve:
• lower MTTR
• fewer false scaling actions
• reduced cascading failures
• more stable autoscaling behavior
• better infrastructure efficiency
Final Thought
Autoscaling is powerful.
But scaling more replicas does not automatically make a system resilient.
If the root cause remains unknown, autoscaling simply spreads the problem faster.
Kubernetes scaling should never replace:
• dependency analysis
• system understanding
• observability correlation
• resilience engineering
Because true reliability comes from understanding system behavior – not just increasing pod count.
👉 To learn more about Kubernetes autoscaling behavior, distributed system bottlenecks, and production incident correlation, follow KubeHA (https://linkedin.com/showcase/kubeha-ara/).
Book a demo today at https://kubeha.com/schedule-a-meet/
Experience KubeHA today: www.KubeHA.com
KubeHA’s introduction, https://www.youtube.com/watch?v=PyzTQPLGaD0
#DevOps #sre #monitoring #observability #remediation #Automation #kubeha #IncidentResponse #AlertRecovery #prometheus #opentelemetry #grafana, #loki #tempo #trivy #slack #Efficiency #ITOps #SaaS #ContinuousImprovement #Kubernetes #TechInnovation #StreamlineOperations #ReducedDowntime #Reliability #ScriptingFreedom #MultiPlatform #SystemAvailability #srexperts23 #sredevops #DevOpsAutomation #EfficientOps #OptimizePerformance #Logs #Metrics #Traces #ZeroCode