What if your Kubernetes dashboard told you why things happen, not just what happened?
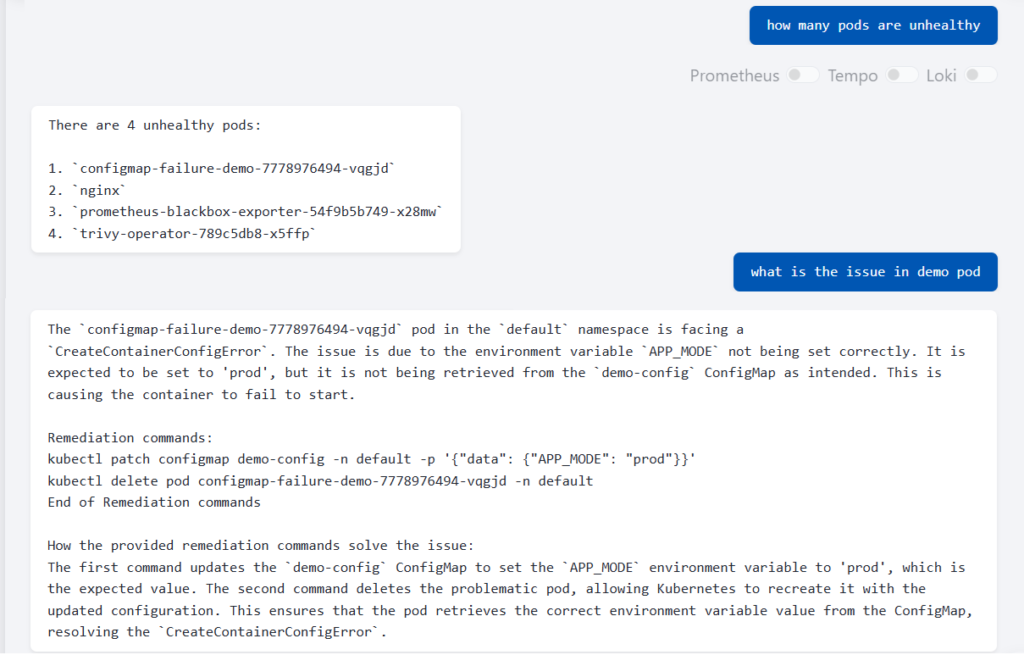
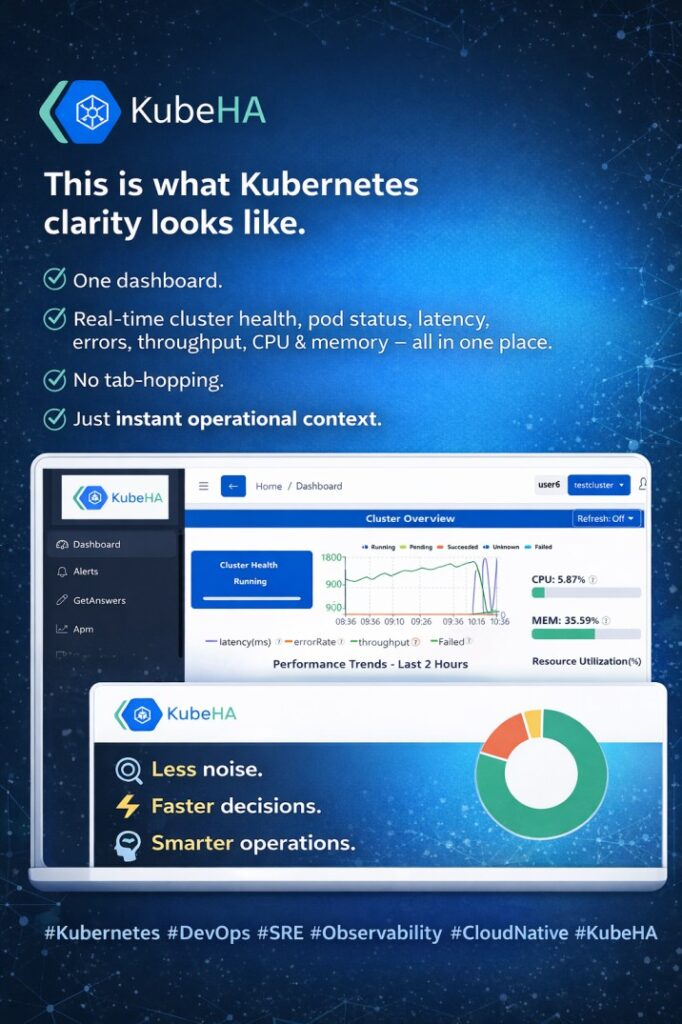
This snapshot is from KubeHA’s Cluster Overview (Yes — this is a real working dashboard) In one view, you can instantly see: Cluster health status (at-a-glance) Latency, error rate & throughput trends Pod health by status (Running / Pending / Failed / Unknown) CPU & memory utilization — clearly, without noise The goal isn’t just […]
What if your Kubernetes dashboard told you why things happen, not just what happened? Read More »