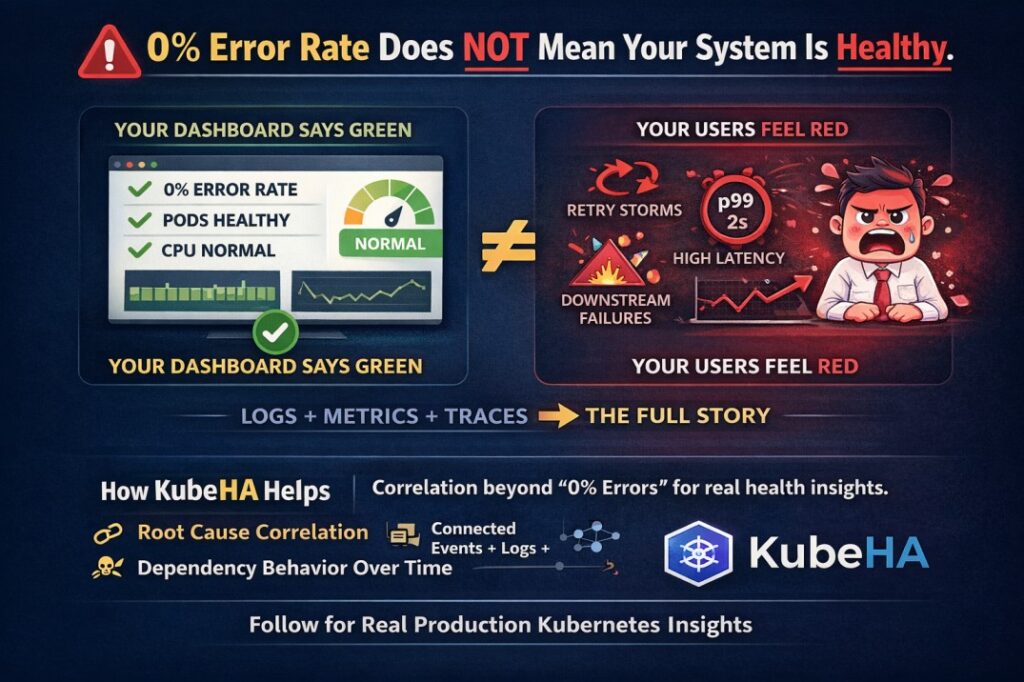
0% Error Rate Does NOT Mean Your System Is Healthy.
This one surprises many teams. You open your dashboard: ✅ Error rate: 0%✅ Pods running✅ CPU normal But users are complaining. Why? Because modern systems hide failure in subtle ways: • Retries mask errors• Circuit breakers absorb failures• Timeouts escalate silently• Tail latency (p95 / p99) explodes• Downstream dependencies degrade slowly• Traffic volume drops silently […]
0% Error Rate Does NOT Mean Your System Is Healthy. Read More »