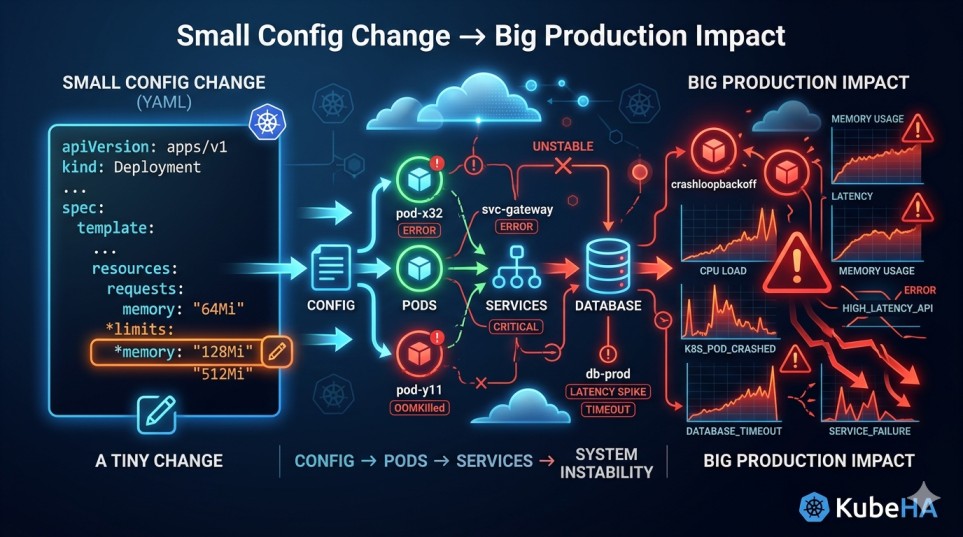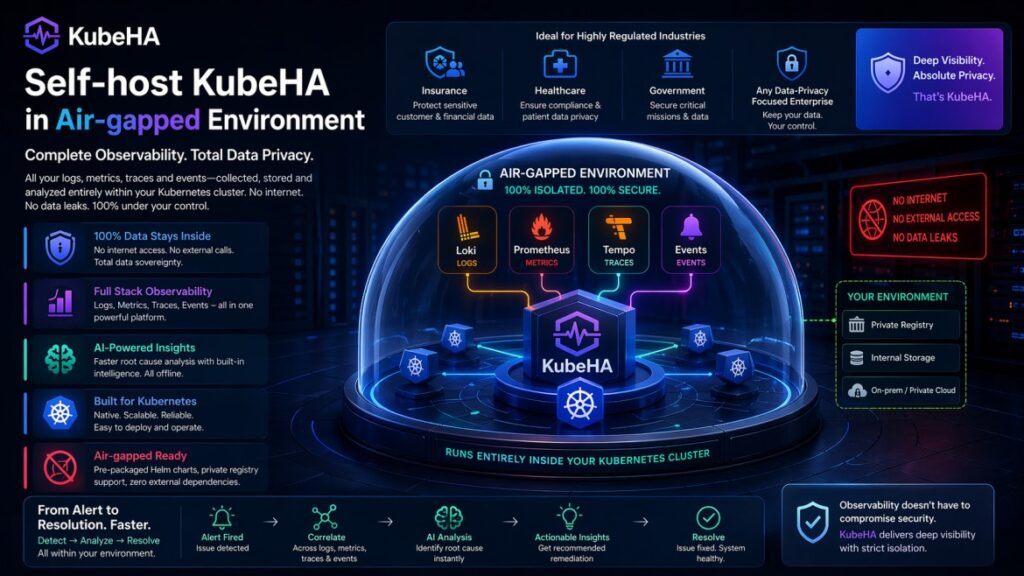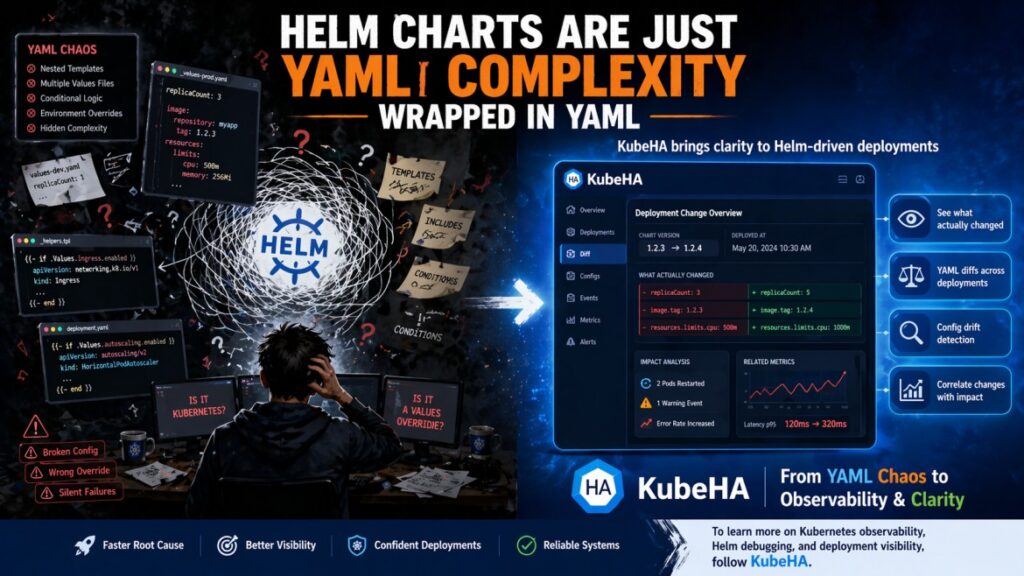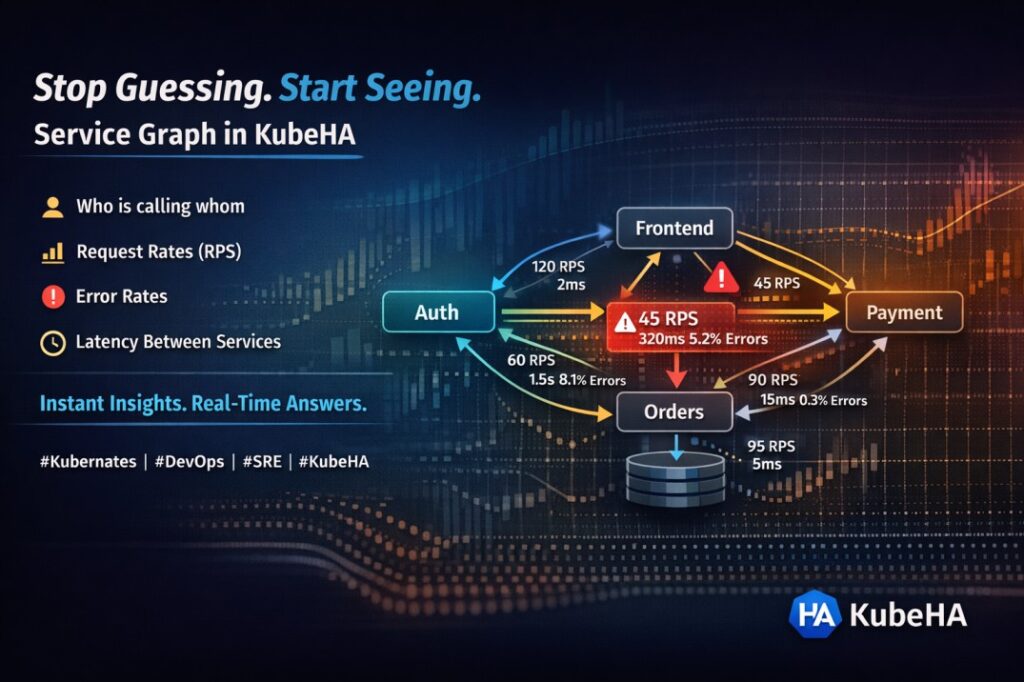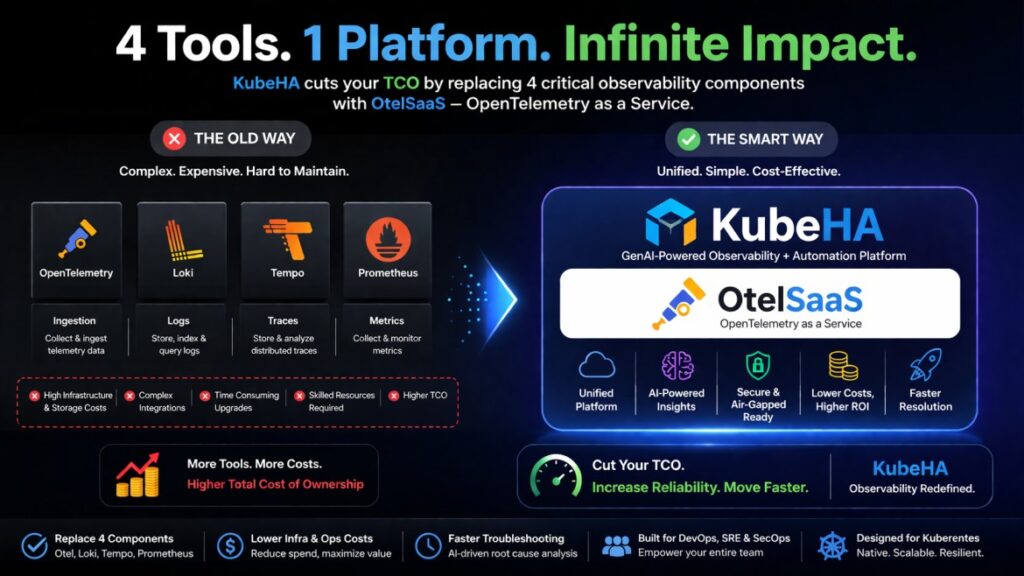
Still Running 4+ Tools for Observability? You’re Paying More Than You Think.
Most teams today stitch together:• OpenTelemetry• Prometheus• Loki• Tempo And then spend months integrating, maintaining, scaling, and troubleshooting them. 👉 That’s not just complexity – that’s hidden TCO (Total Cost of Ownership). 💡 What if you could replace all of this with ONE platform? Introducing KubeHA – your GenAI-powered Observability + Automation platform 🔥 What […]
Still Running 4+ Tools for Observability? You’re Paying More Than You Think. Read More »